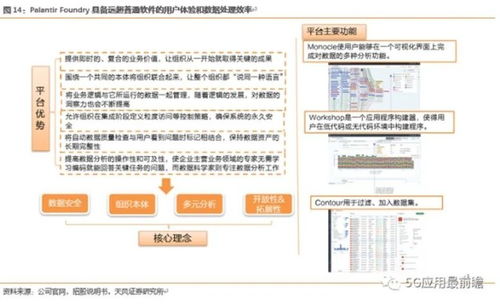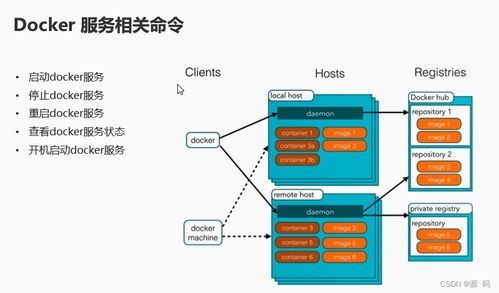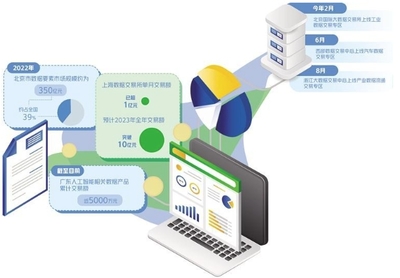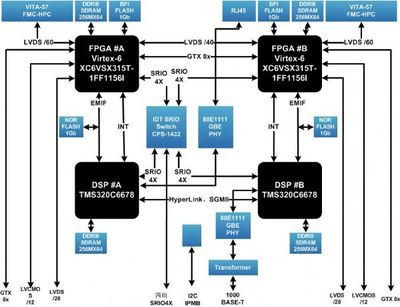
隨著數據量的爆炸式增長和技術架構的持續演進,大數據的發展已邁過早期的數據收集、存儲與基礎分析階段。如今,業界共識正指向一個更為集成和智能化的方向:服務與分析一體化的數據處理服務。這不僅是技術的自然延伸,更是業務需求驅動的必然趨勢,它標志著大數據從“洞察工具”向“價值引擎”的深刻轉變。
一、何為“服務與分析一體化”?
傳統的大數據架構中,數據處理通常遵循一條線性管道:數據采集 → 數據存儲(如數據湖/倉)→ 數據處理與清洗 → 數據分析與建模 → 結果可視化或報告。這條鏈條雖然清晰,但環節割裂,分析結果與應用服務之間存在“最后一公里”的鴻溝。業務部門獲取洞察后,仍需投入大量工程化工作才能將其轉化為可運行的應用程序或自動化決策服務。
“服務與分析一體化”旨在徹底打破這種隔閡。它意味著將數據處理、深度分析與實時服務能力無縫融合在一個統一的平臺或框架內。其核心特征是:
- 閉環智能:分析模型能夠直接驅動業務服務,服務產生的反饋數據又能實時回流,用于模型的優化與迭代,形成一個自我增強的閉環。
- 實時化與操作化:分析不再局限于離線的、面向歷史的報表,而是能夠支持低延遲的實時決策,并直接嵌入到業務流程中(例如,實時風控、個性化推薦、智能運維)。
- 服務化接口:復雜的數據處理與分析能力被封裝成標準的、可調用的API或微服務,業務開發人員可以像調用普通服務一樣,便捷地獲取數據智能,而無需深究底層復雜的分布式計算細節。
- 統一治理與安全:在數據流動、處理、服務化的全鏈條中,實施統一的元數據管理、數據質量監控、訪問權限控制和安全合規保障。
二、驅動一體化趨勢的核心力量
- 業務需求從“描述過去”到“預測與行動”:企業不再滿足于知道“發生了什么”,更迫切地需要知道“將要發生什么”以及“現在該如何行動”。這要求數據分析必須與業務動作緊密結合。
- 技術棧的融合與成熟:云原生、容器化、微服務架構的普及,為靈活部署和編排數據服務提供了基礎。流處理技術(如Apache Flink)、機器學習平臺(MLOps)、服務網格(Service Mesh)的成熟,使得實時分析模型的生產化部署與管理變得可行。
- 成本與效率的考量:割裂的架構導致數據在多個系統間復制、遷移,產生冗余計算和存儲成本,且開發運維復雜。一體化平臺通過統一資源調度和簡化架構,能夠顯著提升資源利用率和開發運維效率。
- 數據平民化的深化:為了讓業務專家、分析師等非技術角色也能直接利用數據能力,必須將分析邏輯產品化為易用的服務,降低使用門檻。
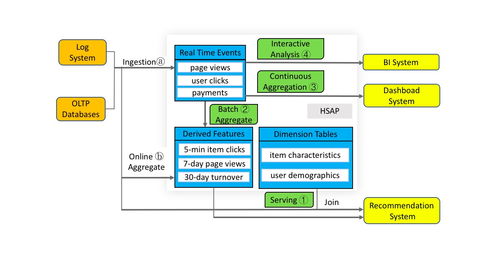
三、一體化數據處理服務的典型架構與場景
一個現代化的一體化數據處理平臺可能呈現以下層次:
- 統一數據層:融合數據湖的靈活性與數據倉庫的性能,支持多模態數據(結構化、半結構化、非結構化)的統一存儲與管理。
- 智能計算層:集成批處理、流處理、交互式查詢和圖計算等多種計算范式,并內置機器學習框架與模型倉庫,支持從訓練到推理的全流程。
- 服務化與API層:將數據處理流水線(ETL/ELT)、分析模型、查詢結果等封裝為RESTful API、GraphQL或事件流,供前端應用、業務系統或其他服務調用。
- 運營與治理層:提供端到端的數據血緣、質量監控、成本分析和統一的安全策略管理。
應用場景示例:
- 金融實時風控:流處理引擎實時分析交易流水,風控模型即時評分,一旦發現可疑交易,風控服務API即刻被調用,觸發攔截或人工審核流程,整個過程在毫秒級完成。
- 電商個性化營銷:用戶行為數據實時流入,推薦模型在線更新用戶畫像,商品推薦服務API根據當前場景(首頁、商品頁、購物車)實時返回個性化列表,直接提升轉化率。
- 工業物聯網預測性維護:設備傳感器數據流被持續分析,異常檢測模型識別潛在故障模式,維護服務自動生成工單并派發至維修人員,實現從感知到行動的自動化。
四、面臨的挑戰與未來展望
邁向服務與分析一體化的道路并非坦途,企業需應對諸多挑戰:
- 技術復雜性:整合多種技術棧并保證高性能、高可用性是一項巨大的工程挑戰。
- 組織與文化壁壘:需要打破數據團隊、分析團隊與業務開發團隊之間的隔閡,向“數據產品團隊”模式轉型。
- 安全與治理:數據服務化后,訪問點增多,數據安全和隱私保護的挑戰加劇。
- 成本控制:實時服務與分析通常消耗更多計算資源,需要精細化的成本優化策略。
大數據的下一站將是一個以“數據即服務”為核心,智能無處不在的生態。人工智能與機器學習將更深地嵌入一體化流程,實現更高級的自動決策。邊緣計算將與云端一體化平臺協同,滿足更低延遲和隱私敏感場景的需求。成功的企業將是那些能夠將數據洞察無縫、實時地轉化為業務行動,并形成持續優化閉環的組織。服務與分析一體化,正是通往這一未來的關鍵路徑。