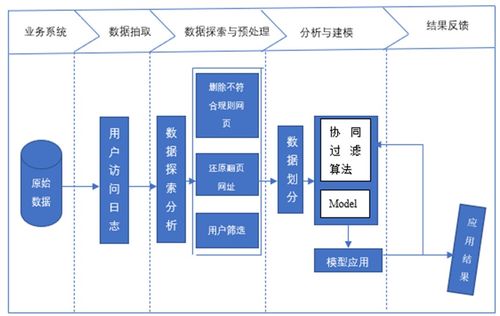
隨著電子商務的蓬勃發展,用戶行為數據的價值日益凸顯。基于協同過濾算法的數據處理服務能夠深入挖掘用戶行為模式,為電商平臺提供精準的個性化推薦,從而提升用戶體驗和平臺效益。
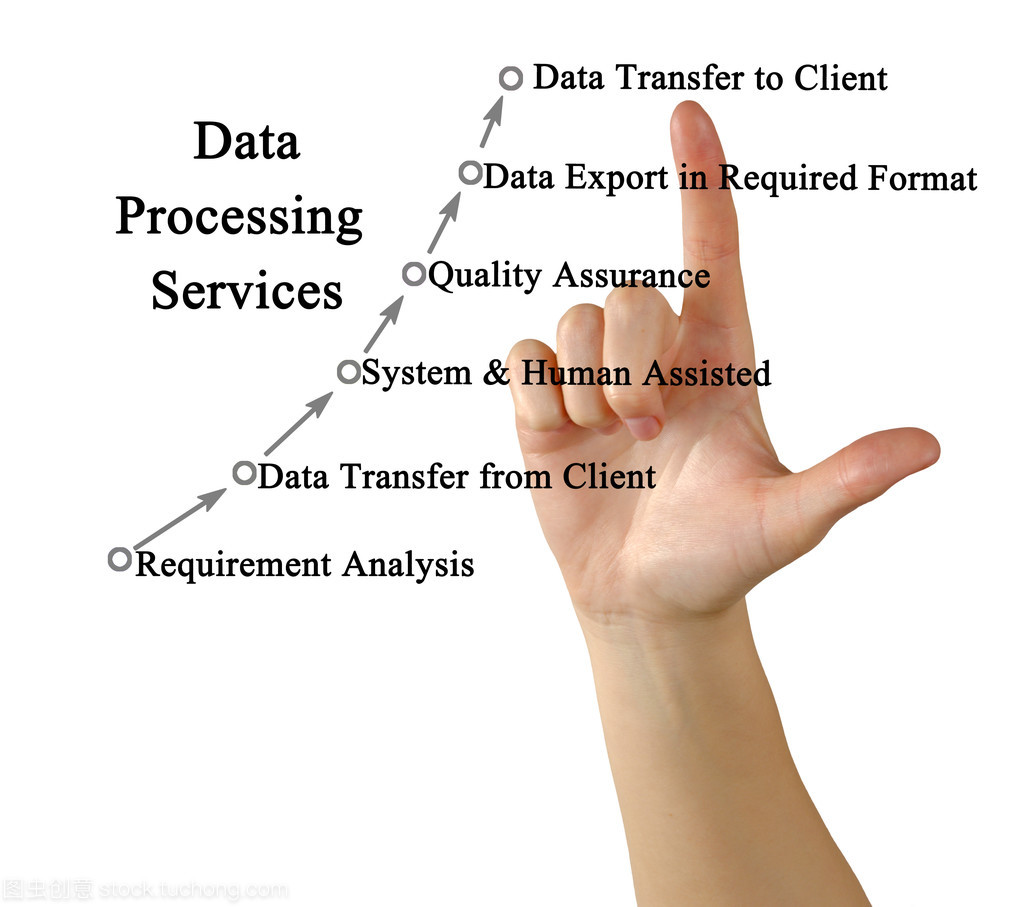
一、數據處理流程
- 數據收集與清洗:整合用戶在電子商務平臺上的行為數據,包括瀏覽記錄、購買歷史、評分和收藏等,并對數據進行去噪、去重和格式化處理。
- 數據轉換與特征提取:將原始行為數據轉換為用戶-物品交互矩陣,提取用戶偏好和物品屬性特征,為協同過濾算法提供輸入。
- 模型訓練:利用協同過濾算法(如基于用戶的協同過濾或基于物品的協同過濾)訓練推薦模型,識別用戶之間的相似性或物品之間的關聯性。
二、智能推薦實現
- 相似度計算:通過余弦相似度或皮爾遜相關系數等方法,計算用戶或物品之間的相似度。
- 預測與推薦生成:基于相似用戶或物品的行為,預測目標用戶對未交互物品的偏好,并生成Top-N推薦列表。
- 實時更新與優化:結合增量學習技術,實時處理新用戶行為數據,動態調整推薦結果,并利用A/B測試評估推薦效果。
三、服務優勢與應用
該數據處理服務能夠有效解決信息過載問題,提高用戶粘性和轉化率。其優勢包括個性化程度高、易于擴展和適用性廣。典型應用包括商品推薦、促銷活動定向和用戶畫像構建,為電子商務平臺的智能化運營提供核心支持。
基于協同過濾算法的數據處理服務是電子商務智能推薦系統的關鍵組成部分,通過高效的數據處理和算法應用,助力平臺實現精準營銷和用戶體驗優化。