數據倉庫架構的發展歷程反映了企業數據處理需求的不斷演進和技術創新。從早期的簡單結構到如今高度集成的云原生解決方案,數據倉庫的演變不僅提升了數據處理效率,也深刻影響了現代企業的數據管理方式。
早期數據倉庫架構采用單一集中式模式,如Bill Inmon提出的企業信息工廠模型,強調數據集成和一致性。這種架構通過ETL(抽取、轉換、加載)流程,將來自不同業務系統的數據整合到中央存儲庫中。雖然這種模式提供了統一的數據視圖,但在處理大規模數據和實時分析方面存在局限性。
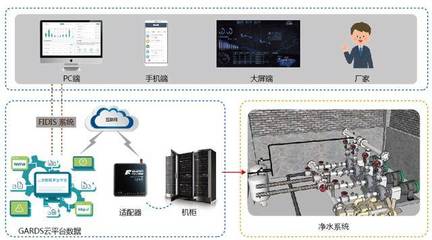
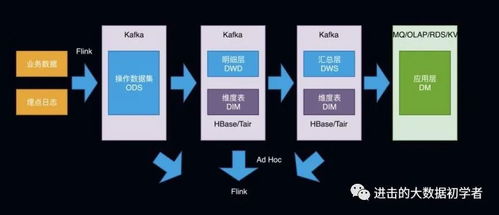
隨著數據量激增和處理需求多樣化,數據倉庫架構逐步發展為分層結構。典型的分層包括數據接入層、數據存儲層和數據服務層。數據接入層負責從各種數據源采集數據;數據存儲層采用星型或雪花型模型組織數據;數據服務層則提供查詢、分析和報表功能。這種分層架構提高了系統的可擴展性和維護性。
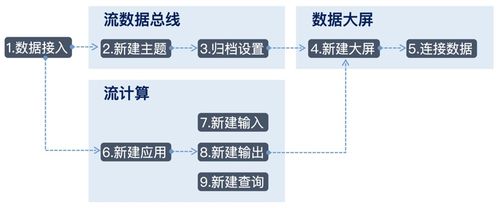
大數據時代的到來催生了新一代數據倉庫架構。以Lambda架構和Kappa架構為代表,這些架構支持批處理和流處理的混合模式。Lambda架構通過批處理層和速度層分別處理歷史數據和實時數據;Kappa架構則統一使用流處理技術,簡化了系統復雜度。這些架構能夠應對海量數據的實時處理需求。
云計算的普及推動了云原生數據倉庫的興起。Snowflake、BigQuery等云數據倉庫采用存儲與計算分離的架構,實現了彈性擴展和按需付費。這種架構不僅降低了運維成本,還提供了更強的并發處理能力和跨地域數據共享功能。
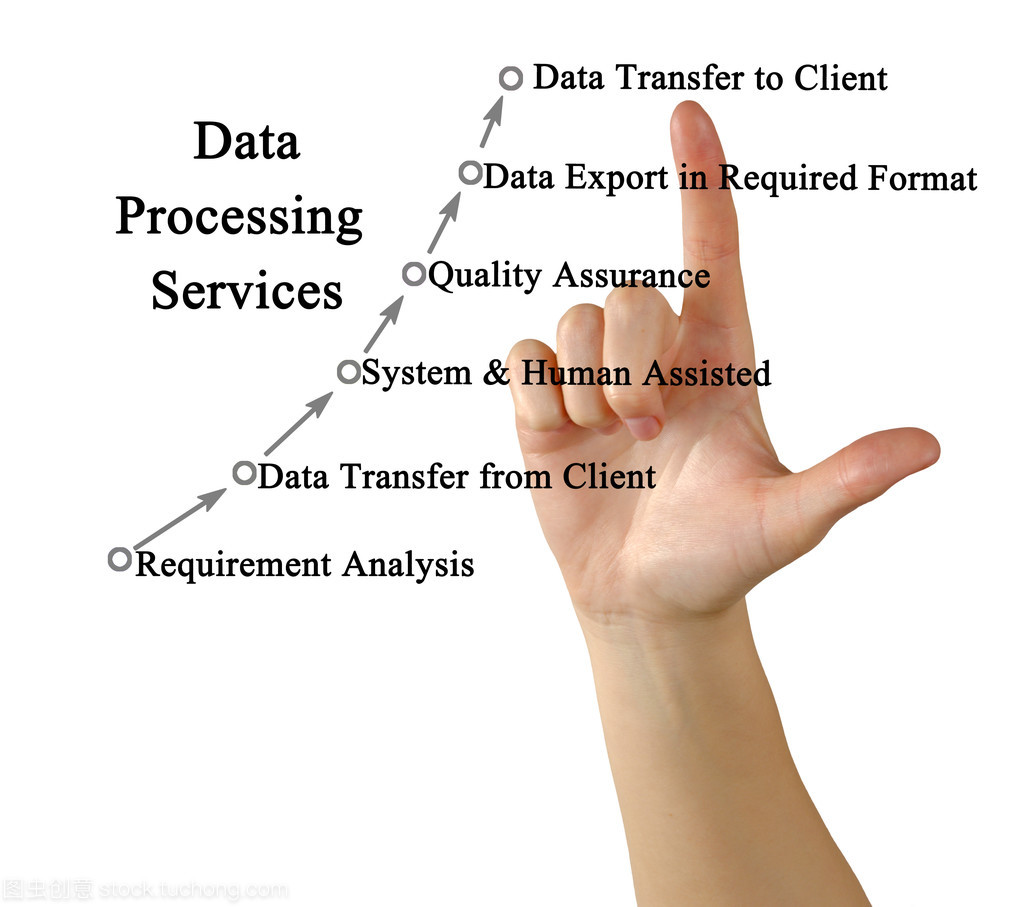
在數據處理服務方面,現代數據倉庫已發展出豐富的服務生態:
- 數據集成服務:提供數據抽取、轉換和加載能力,支持多種數據源和實時數據流。
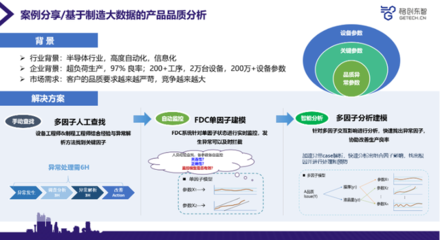
- 數據質量管理服務:確保數據的準確性、完整性和一致性。
- 元數據管理服務:維護數據字典、血緣分析和數據治理信息。
- 數據安全服務:實施數據加密、訪問控制和合規性管理。
- 分析與可視化服務:支持SQL查詢、機器學習分析和交互式報表。
未來,數據倉庫架構將繼續向智能化、自動化和實時化方向發展。AI驅動的數據管理、自動化運維和實時數據處理將成為新的技術焦點。同時,數據倉庫與數據湖的融合架構(Lakehouse)正在成為主流趨勢,結合了數據倉庫的結構化處理能力和數據湖的靈活性。
數據倉庫架構的發展始終圍繞著提升數據處理效率、降低運維成本和滿足業務需求這三個核心目標。隨著技術的不斷進步,數據處理服務將變得更加智能、高效和易用,為企業的數字化轉型提供更強有力的支撐。